# télécharger le dataset
download.file("https://github.com/antuki/RR2023_tuto_statspatiale/raw/main/exercises/data.zip",
destfile = "data.zip")
# dézipper
unzip("data.zip",exdir=".") Atelier R Statistique spatiale et Cartographie
Rencontres R Juin 2023
La base de données utilisée dans ce TP concerne la géolocalisation des accidents de la route à Paris. Il s’agit plus précisément des bases de données annuelles des accidents corporels de la circulation routière, en particulier le millésime 2019.
« Pour chaque accident corporel (soit un accident survenu sur une voie ouverte à la circulation publique, impliquant au moins un véhicule et ayant fait au moins une victime ayant nécessité des soins), des saisies d’information décrivant l’accident sont effectuées par l’unité des forces de l’ordre (police, gendarmerie, etc.) qui est intervenue sur le lieu de l’accident. Ces saisies sont rassemblées dans une fiche intitulée bulletin d’analyse des accidents corporels. L’ensemble de ces fiches constitue le fichier national des accidents corporels de la circulation dit « Fichier BAAC » administré par l’Observatoire national interministériel de la sécurité routière “ONISR”.
Un certain nombre d’indicateurs issus de cette base font l’objet d’une labellisation par l’autorité de la statistique publique (arrêté du 27 novembre 2019). »
Vous pouvez télécharger les bases de données brutes ici ou utiliser R pour les télécharger dans votre dossier actuel :
Exercice 1 : Manipuler des objets sf
Indice
Utilisez la fonction sf::st_read().
Solution
library(sf)
iris.75 <- st_read("data/iris_75.shp", quiet = TRUE,
stringsAsFactors = F)
Solution
plot(iris.75)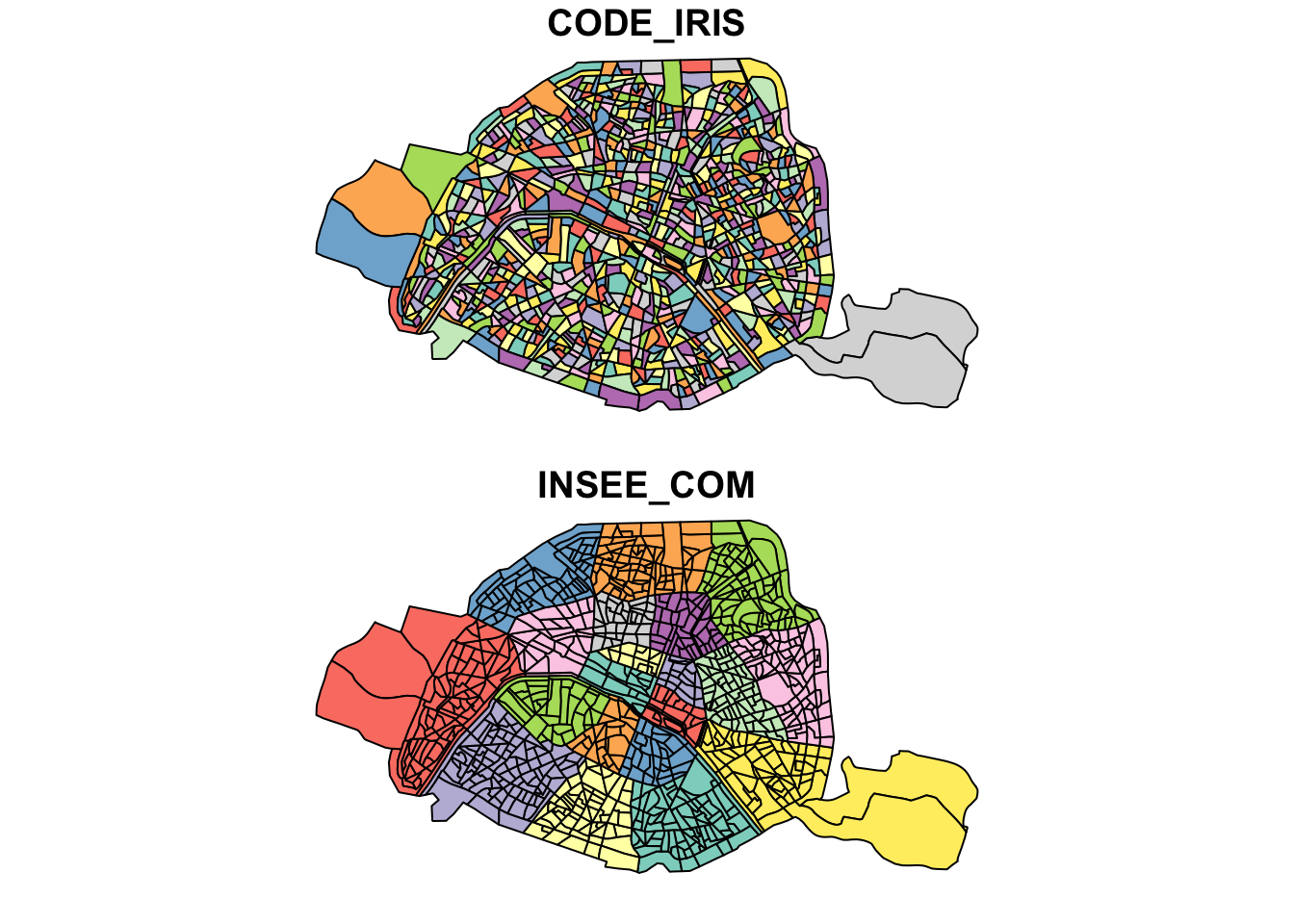
On remarque que R fait plusieurs graphiques : un par variable contenue dans l’objet sf.
Solution
sf::st_geometry() permet d’isoler l’information contenue dans la colonne geometry de l’objet sf. Cela permet de mettre de côté les autres variables et de n’en afficher qu’une.
plot(st_geometry(iris.75))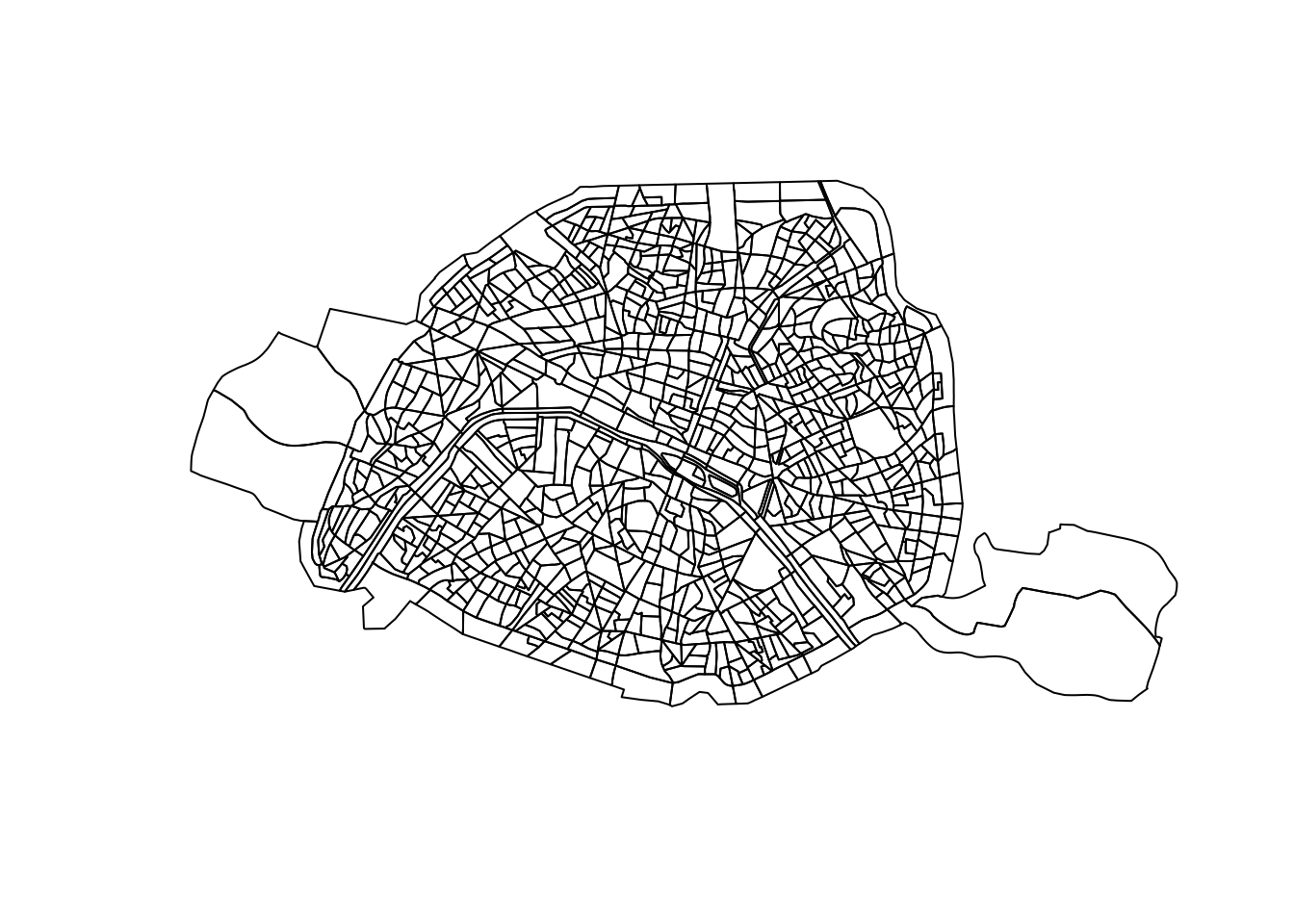
Indice
Utilisez sf::st_read() et sf::st_geometry(). Vous pouvez aussi customiser la carte en utilisant différents paramètres de la fonction plot : bg, col, lwd, border, pch, cex…
Solution
accidents.2019.paris <- st_read("data/accidents2019_paris.geojson",
quiet = TRUE)plot(st_geometry(iris.75), bg = "cornsilk", col = "lightblue",
border = "white", lwd = .5)
plot(st_geometry(accidents.2019.paris), col = "red", pch = 20, cex = .2, add=TRUE)
title("Accidents à Paris")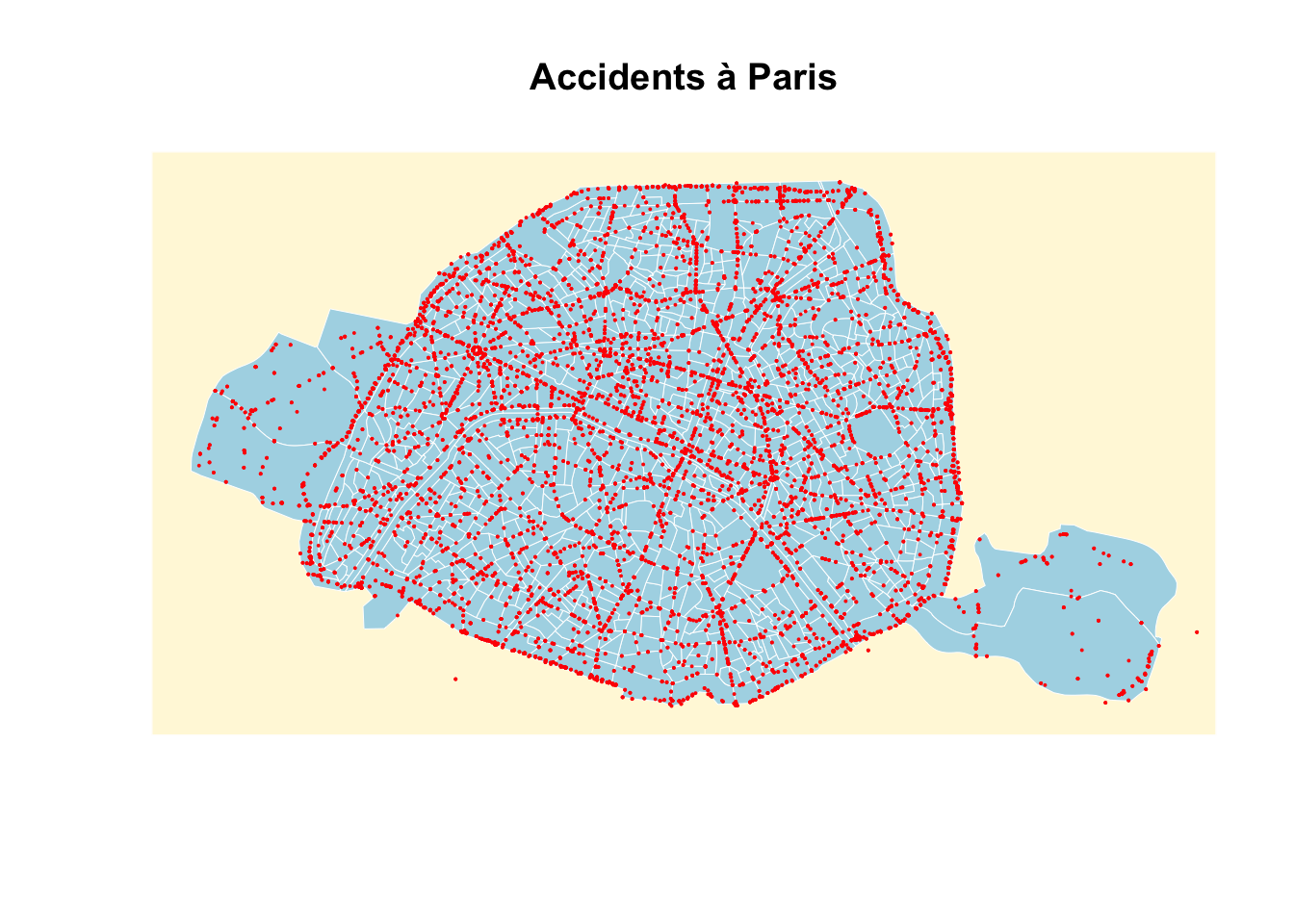
Indice
Utilisez les fonctions st_union, st_buffer, st_voronoi, st_collection_extract, st_interection, st_join et st_centroid.
Solution
# 1. Carte agrégée Paris
iris.75.u <- st_union(iris.75)
# 2. Zone tampon de 1km
iris.75.b <- st_buffer(x = iris.75.u, dist = 1000)
# 3. Centroïdes
iris.75.c <- st_centroid(iris.75)Warning: st_centroid assumes attributes are constant over geometries# 4. Distance entre centroïdes
mat <- st_distance(x=iris.75.c, y=iris.75.c)
# 5. Calculer les polygones de Voronoïs autour des centroïdes
iris.75.v <- st_collection_extract(st_voronoi(x = st_union(iris.75.c)))
iris.75.v <- st_intersection(iris.75.v,iris.75.u)# Affichage des cartes
plot(st_geometry(iris.75.b), lwd=2, border ="red",col=NA)
plot(st_geometry(iris.75), ltw=5, col="#999999", add = TRUE)
plot(st_geometry(iris.75.u), border="blue", ltw=5, col=NA, add = TRUE)
plot(st_geometry(iris.75.c), pch = 20, cex = .2,col="red", add = TRUE)
plot(st_geometry(iris.75.v), ltw=5, col=NA,border="blue", add = TRUE)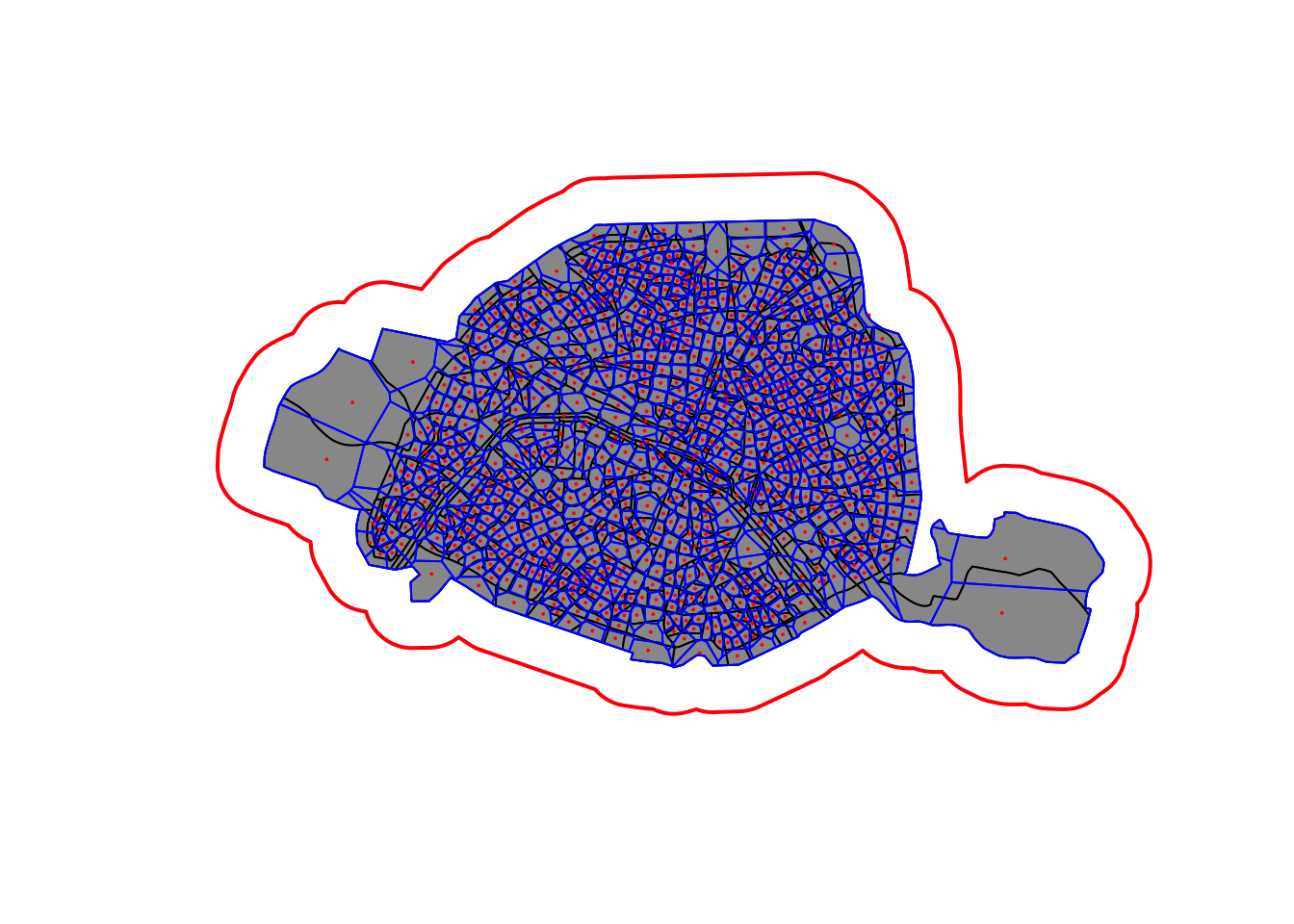
Information
La couche cartographique ‘iris.75’ contient un code de 5 chiffres dans sa variable INSEE_COM qui correspond au code de l’arrondissement.
Documentation de la variable grav : Gravité de blessure de l’usager, les usagers accidentés sont classés en trois catégories de victimes plus les indemnes :
- 1 : Indemne
- 2 : Tué
- 3 : Blessé hospitalisé
- 4 : Blessé léger
Indice
Utilisez sf::st_join() (jointure spatiale) et également des fonctions du package classique dplyr :
dplyr::selectdplyr::group_bydplyr::summarisedplyr::left_join.
Ces fonctions fonctionnent également avec les objets sf.
Solution
library(dplyr)
# Jointure spatiale ?st_join via ?st_intersects
accidents.2019.paris.iris <- iris.75 |> st_join(accidents.2019.paris,
join = st_intersects)
str(accidents.2019.paris.iris)Classes 'sf' and 'data.frame': 11971 obs. of 14 variables:
$ CODE_IRIS : chr "751197316" "751197316" "751197316" "751197316" ...
$ INSEE_COM : chr "75119" "75119" "75119" "75119" ...
$ Num_Acc : num 2.02e+11 2.02e+11 2.02e+11 2.02e+11 2.02e+11 ...
$ id_vehicule: chr "138 271 825" "138 271 825" "138 234 336" "138 234 337" ...
$ grav : num 4 1 1 4 4 1 4 4 1 1 ...
$ sexe : chr "Masculin" "Masculin" "Masculin" "Masculin" ...
$ an_nais : num 1989 1959 1936 1985 1994 ...
$ com : chr "75119" "75119" "75119" "75119" ...
$ int : chr "Intersection en T" "Intersection en T" "Intersection en X" "Intersection en X" ...
$ lum : chr "Plein jour" "Plein jour" "Plein jour" "Plein jour" ...
$ voie : chr "RUE CURIAL" "RUE CURIAL" "RUE DE CRIMEE" "RUE DE CRIMEE" ...
$ catr : num 4 4 4 4 4 4 4 4 4 4 ...
$ catv : chr "Scooter > 50 cm 3 et <= 125 cm 3" "Scooter > 50 cm 3 et <= 125 cm 3" "VL seul" "Bicyclette" ...
$ geometry :sfc_MULTIPOLYGON of length 11971; first list element: List of 1
..$ :List of 1
.. ..$ : num [1:23, 1:2] 653971 653973 653986 653994 653996 ...
..- attr(*, "class")= chr [1:3] "XY" "MULTIPOLYGON" "sfg"
- attr(*, "sf_column")= chr "geometry"
- attr(*, "agr")= Factor w/ 3 levels "constant","aggregate",..: NA NA NA NA NA NA NA NA NA NA ...
..- attr(*, "names")= chr [1:13] "CODE_IRIS" "INSEE_COM" "Num_Acc" "id_vehicule" ...# agrégation par CODE_IRIS
accidents.2019.paris.iris <- accidents.2019.paris.iris |>
# Pour accélérer le traitement : On peut supprimer la géométrie
# des IRIS avant l'agrégation et la rajouter par la suite
st_drop_geometry() |>
group_by(CODE_IRIS) |>
summarise(nbacc=n(), nbaccnb = sum(grav==1)) |>
# On remet la géométrie des IRIS
left_join(iris.75 |> select(CODE_IRIS, INSEE_COM)) |>
st_as_sf()Joining with `by = join_by(CODE_IRIS)`head(accidents.2019.paris.iris)Simple feature collection with 6 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 650181.1 ymin: 6861761 xmax: 652179 ymax: 6863138
Projected CRS: RGF93 v1 / Lambert-93
# A tibble: 6 × 5
CODE_IRIS nbacc nbaccnb INSEE_COM geometry
<chr> <int> <int> <chr> <MULTIPOLYGON [m]>
1 751010101 27 14 75101 (((652130.3 6862122, 652126.1 6862116, 6521…
2 751010102 16 6 75101 (((651807.7 6861881, 651668.7 6862071, 6516…
3 751010103 17 8 75101 (((651639.9 6862522, 651666.9 6862508, 6517…
4 751010104 26 13 75101 (((651134.9 6862419, 650895 6862502, 650854…
5 751010105 14 6 75101 (((650850.3 6862538, 650849.7 6862532, 6508…
6 751010199 28 15 75101 (((650833.2 6862444, 650696 6862519, 650544…
Solution
library(dplyr)
accidents.2019.paris.arr <- accidents.2019.paris.iris |>
group_by(INSEE_COM) |>
summarize(nbacc = sum(nbacc, na.rm=TRUE),
nbaccnb = sum(nbaccnb, na.rm=TRUE))
head(accidents.2019.paris.arr)Simple feature collection with 6 features and 3 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 649855.9 ymin: 6859834 xmax: 653707.7 ymax: 6863752
Projected CRS: RGF93 v1 / Lambert-93
# A tibble: 6 × 4
INSEE_COM nbacc nbaccnb geometry
<chr> <int> <int> <POLYGON [m]>
1 75101 285 134 ((650257 6862732, 650181.1 6862768, 650208.6 6862824,…
2 75102 173 76 ((651769.9 6863020, 651741.2 6863031, 651701 6863047,…
3 75103 202 85 ((652805.5 6862427, 652773.9 6862443, 652688.9 686248…
4 75104 277 108 ((652705.9 6861376, 652544.5 6861441, 652420.3 686148…
5 75105 234 102 ((652395.6 6859839, 652364.6 6859842, 652225.6 685986…
6 75106 273 127 ((650807.6 6860419, 650795.2 6860425, 650752.3 686044…plot(st_geometry(accidents.2019.paris.iris),
col = "ivory3", border = "ivory1")
plot(st_geometry(accidents.2019.paris.arr),
col = NA, border = "ivory4", lwd = 2, add = TRUE)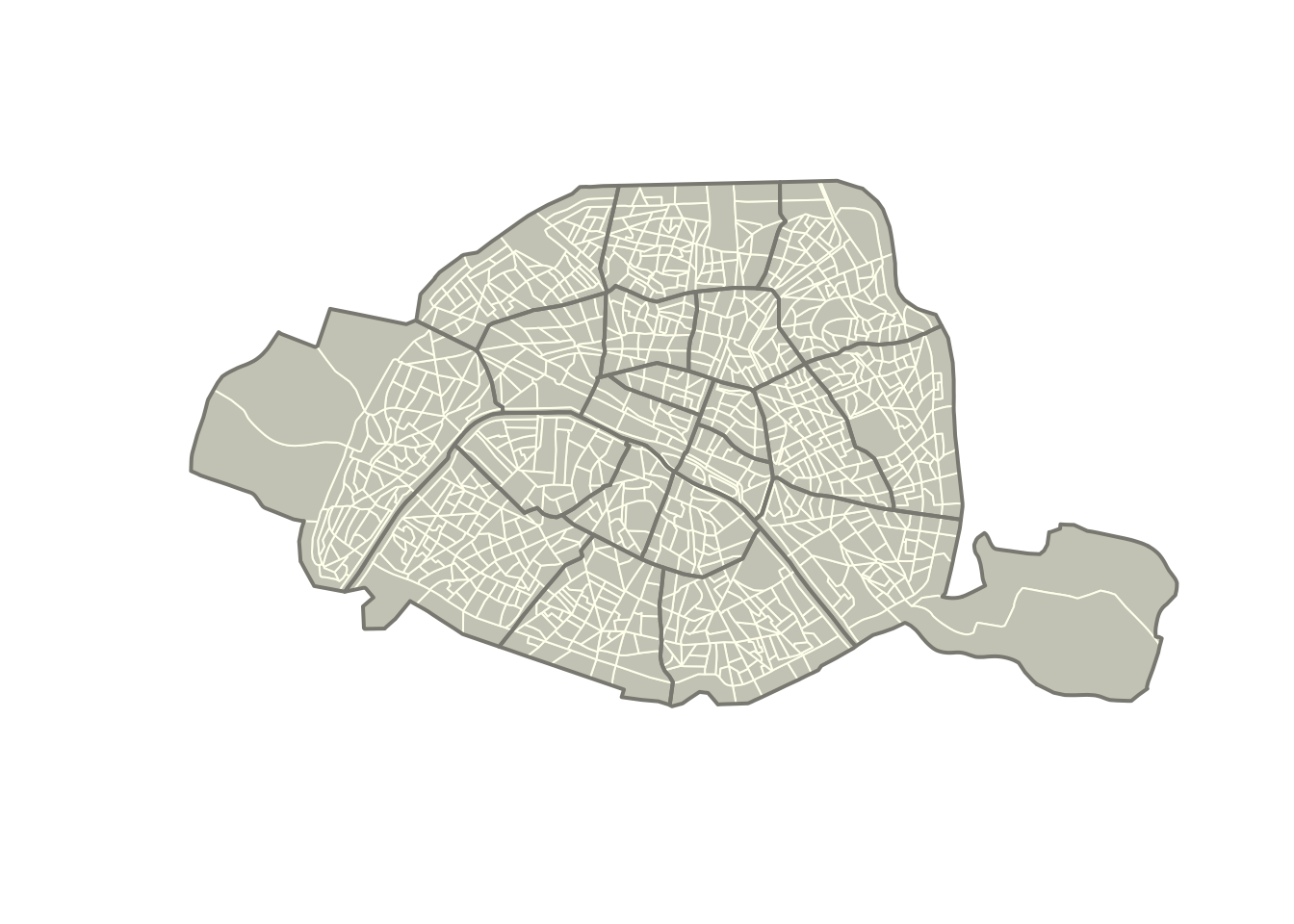
Exercice 2 : Cartes interactives
Dans cet exercice, nous allons utiliser mapview pour explorer les accidents de la route ayant eu lieu à Paris en 2019.
Information
Par exemple, vous pouvez utiliser les paramètres map.types, col.regions, label, color, legend, layer.name, homebutton, lwd, alpha, zcol … du package mapview pour reproduire la carte ci-dessous.
Solution
library(mapview)
library(sf)
accidents.2019.paris <- st_read("data/accidents2019_paris.geojson",
quiet = TRUE)
m <- mapview(accidents.2019.paris |>
mutate(grav_f = factor(grav,
levels = c(2,3,4,1),
labels = c("Tué", "Blessé hospitalisé",
"Blessé léger","Indemne")
)),
col.regions = c("darkred","red","orange","darkgreen"),
label = accidents.2019.paris$Num_Acc,
color = "white", legend = TRUE,
zcol="grav_f", alpha=0.9,
map.types = "Stamen.TonerLite",
layer.name = "Gravite",
homebutton = FALSE, lwd = 0.2)mRemarque : ici seuls 100 points sont affichés pour alléger le fichier .html
Exercice 3 : Cartes ggplot2
Nous cherchons à réaliser une carte des arrondissements de Paris qui combine le nombre de personnes accidentées et la part de celles qui n’ont pas été blessées.
Indice
Pour la création de bks et de cols, utilisez les fonctions quantile et RColorBrewer::brewer.pal. Pour la création de la variable typo, vous pouvez utiliser la fonction cut avec les paramètres digit.lab = 2 et include.lowest = TRUE.
Solution
library(sf)
# 1. Importer les données et créer la variable part_non_blesses
com.75 <- st_read("data/com_75.shp", quiet = TRUE)
com.75$part_non_blesses <- 100 * com.75$nbaccnb / com.75$nbacc
# 2. Définir les bks par quantile
bks <- quantile(com.75$part_non_blesses, na.rm = TRUE, probs=seq(0,1,0.25))
# 3. Définir une palette de couleurs
library(RColorBrewer)
cols <- brewer.pal(length(bks)-1,"Greens")
# 4. Variable typo
library(dplyr)
com.75 <- com.75 |>
mutate(typo = cut(part_non_blesses,
breaks = bks,
labels = paste0(
round(bks[1:(length(bks)-1)]),
" à ",round(bks[2:length(bks)])
),
include.lowest = TRUE))
Solution
library(ggplot2)
map_ggplot <- ggplot() +
geom_sf(data = com.75, aes(fill = typo), colour = "grey80") +
scale_fill_manual(name = "Part des non-blessés parmi les\naccidentés de la route (en %)",
values = cols) +
geom_sf(data = com.75 |> st_centroid(),
aes(size = nbacc), fill = "#f5f5f5", color = "grey20", shape = 21,
stroke = 1, alpha = 0.8, show.legend = "point") +
scale_size_area(max_size = 12, name = "Nombre de personnes\n accidentées") +
coord_sf(crs = 2154, datum = NA,
xlim = st_bbox(com.75)[c(1,3)],
ylim = st_bbox(com.75)[c(2,4)]) +
theme_minimal() +
theme(panel.background = element_rect(fill = "cornsilk", color = NA),
legend.position = "bottom", plot.background = element_rect(fill = "cornsilk",color=NA)) +
labs(title = "Accidents de la route à Paris en 2019",
caption = "fichier BAAC 2019, ONISR\nantuki & comeetie, 2021") +
guides(size = guide_legend(label.position = "bottom", title.position = "top",
override.aes = list(alpha = 1, color = "#ffffff")),
fill = guide_legend(label.position = "bottom", title.position = "top"))Warning: st_centroid assumes attributes are constant over geometriesplot(map_ggplot)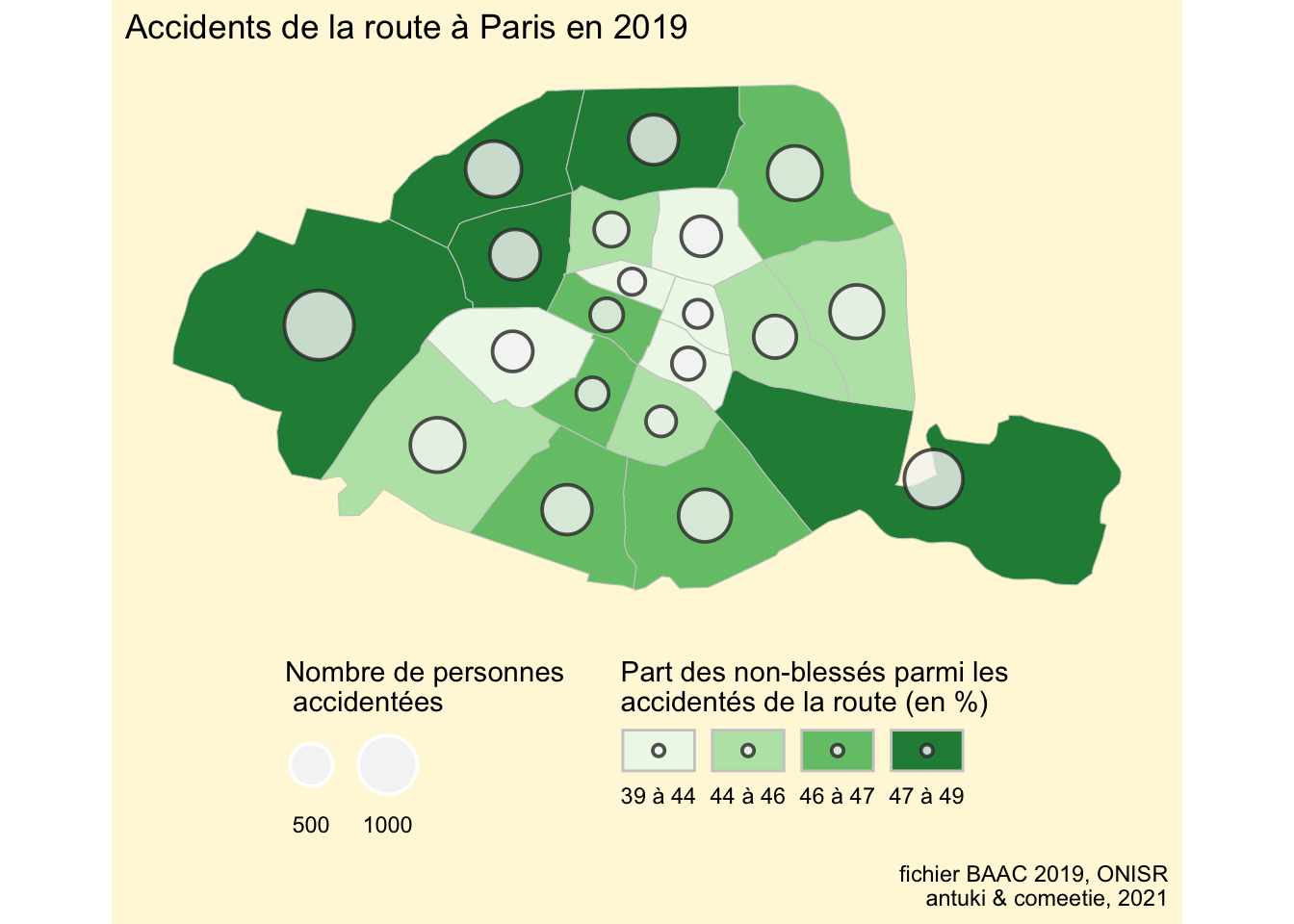
Solution
library(mapsf)
mf_theme("default",cex=0.9,mar=c(0,0,1.2,0),bg="ivory")
#mf_init(x = com.75, theme = "ink", expandBB = c(0, 0, 0, .15))
mf_map(
x = com.75,
var = "part_non_blesses",
type = "choro",
border = "grey80",
lwd = 0.1,
leg_pos = c("topright"),
leg_title = c("Part des non-blessés parmi les\naccidentés de la route (en %)"),
breaks = "quantile",
nbreaks = 4,
pal = "Greens",
leg_val_rnd = 0,
leg_frame = TRUE
)
mf_map(
x = com.75 |> st_centroid(),
var = "nbacc",
type = "prop",
border = "grey20",
lwd = 0.1,
leg_pos = c("right"),
leg_title = c("Nombre de personnes\n accidentées"),
col = "#f5f5f5",
leg_val_rnd = 0,
leg_frame = TRUE
)
mf_layout(
title = "Accidents de la route à Paris en 2019",
credits = "fichier BAAC 2019, ONISR\nantuki & comeetie, 2023",
frame = TRUE)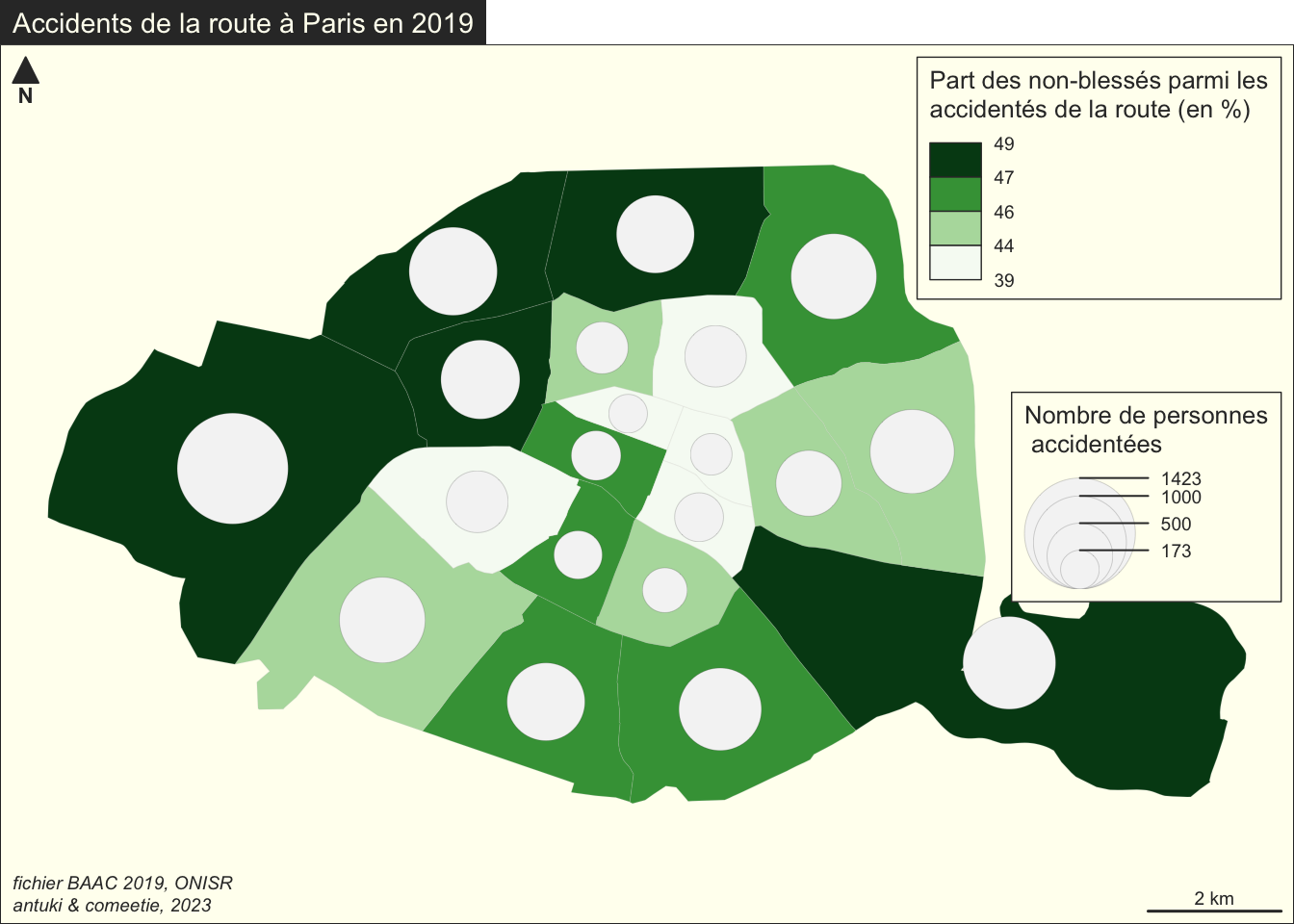
Exercices BONUS
Exercice A : Géocodage
Information
Utilisez les deux méthodes de géocodage :
library(banR)pour interroger l’API de la BAN françaiselibrary(tidygeocoder)pour les adresses internationales
Solution
base_a_geocoder <- accidents.2019.paris |>
filter(grav == 1 & com == "75102")
# Avec banR
#remotes::install_github("joelgombin/banR")
library(banR)
base_a_geocoder |>
banR::geocode_tbl(adresse = voie,code_insee = com) |>
select(latitude,longitude) |>
head()Writing tempfile to.../var/folders/24/8k48jl6d249_n_qfxwsl6xvm0000gn/T//RtmpzUFxyP/file764b7846e57f.csvIf file is larger than 50 MB, it must be splitted
Size is : 5.1 KbSuccessOKSuccess: (200) OKNew names:
• `geometry` -> `geometry...10`
• `geometry` -> `geometry...13`# A tibble: 6 × 2
latitude longitude
<dbl> <dbl>
1 48.9 2.35
2 48.9 2.33
3 48.9 2.35
4 48.9 2.33
5 48.9 2.35
6 48.9 2.35# Avec tidygeocoder
# install.packages("tidygeocoder")
library(tidygeocoder)
base_a_geocoder %>%
mutate(addr = paste(voie, ", Paris, France")) %>%
tidygeocoder::geocode(addr,method = "osm") %>% select(lat, long) %>%
head()Passing 32 addresses to the Nominatim single address geocoder
Query completed in: 34 seconds# A tibble: 6 × 2
lat long
<dbl> <dbl>
1 48.9 2.35
2 48.9 2.33
3 48.9 2.35
4 48.9 2.33
5 48.9 2.35
6 48.9 2.36Exercice B : Open Street Map
Indice
Utilisez sf::st_bbox() et sf::st_transform() pour extraire la bounding box. Le code epsg de WGS84 est 4326.
Solution
bb <- iris.75 %>% st_transform(4326) %>% st_bbox()
Indice
Utilisez :
osmdata:opq()pour définir la bounding box de la requête osmosmdata:add_osm_feature()pour définir la paire key:value recherchéeosmdata:osmdata_sf()pour récupérer les données osm.
Solution
library(osmdata)
q <- opq(bbox = bb,timeout = 180)
qt <- add_osm_feature (q, key = 'highway',value = 'trunk', value_exact = FALSE)
roads <- c(osmdata_sf(qt))$osm_lines %>% st_transform(st_crs(iris.75))
Encoding(roads$name) <- "UTF-8" #si problème d'encodage
Solution
periph <- roads %>%
filter(name=="Boulevard Périphérique Extérieur") %>% st_geometry %>%
st_buffer(50)
accidents.2019.paris.periph <- st_intersection(accidents.2019.paris, periph)Warning: attribute variables are assumed to be spatially constant throughout
all geometriesplot(st_geometry(accidents.2019.paris.periph))
Exercice C : Carroyage et lissage spatial avec btb
Ce tutoriel vous donne davantage de détails sur le carroyage et le lissage spatial.
Indice
Utilisez successivement les fonctions :
btb::btb_add_centroidspour associer à chaque point le centroïde de son futur carreaudplyr::countpour compter le nombre d’accidents avec ungroup_by(x_centro, y_centro)btb::btb_ptsToGridpour transformer les données en grille
Solution
# On ajoute les centroïdes des futurs carreaux de 500m dans la base
points_carroyage <- btb::btb_add_centroids(
pts = accidents.2019.paris, iCellSize = 500)
# On compte le nombre d'accidents par centroïde
points_centroides <- points_carroyage %>% st_drop_geometry() %>%
group_by(x_centro,y_centro) %>% count(name = "nbacc")
# On crée la grille
carreaux <- btb::btb_ptsToGrid(pts = points_centroides,
sEPSG = "2154", iCellSize = 500)
# On cartographie
library(mapsf)
mf_theme("default",cex=0.9,mar=c(0,0,1.2,0),bg="ivory")
mf_init(x=carreaux)
mf_map(x = carreaux,
type = "choro",
var="nbacc",
breaks = "quantile",
border = NA,
nbreaks = 5,
lwd=1,
leg_val_rnd = 1,
add = TRUE)
mf_layout(
title = "Carroyage d'accidents de la route à Paris en 2019",
credits = "fichier BAAC 2019, ONISR\nantuki & comeetie, 2023")
Indice
Utilisez uniquement la fonction btb::btb_smooth qui réalise directement le carroyage et le lissage sans avoir cette fois-ci besoin d’étapes intermédiaires.
Solution
# Lissage spatial. Carreaux 500m / Lissage 1 km
carreaux_lisses <- btb::btb_smooth(
pts = accidents.2019.paris %>% mutate(nbacc = 1) %>% select(nbacc),
sEPSG = "2154",iCellSize = 500, iBandwidth = 1000)# Cartographie
mf_theme("default",cex=0.9,mar=c(0,0,1.2,0),bg="ivory")
mf_init(x=carreaux)
mf_map(x = carreaux_lisses,
type = "choro",
var="nbacc",
border = NA,
breaks = "quantile",
nbreaks = 5,
lwd=1,
add = TRUE)
mf_layout(
title = "Lissage avec rayon de 1km des\naccidents de la route à Paris en 2019",
credits = "fichier BAAC 2019, ONISR\nantuki & comeetie, 2023")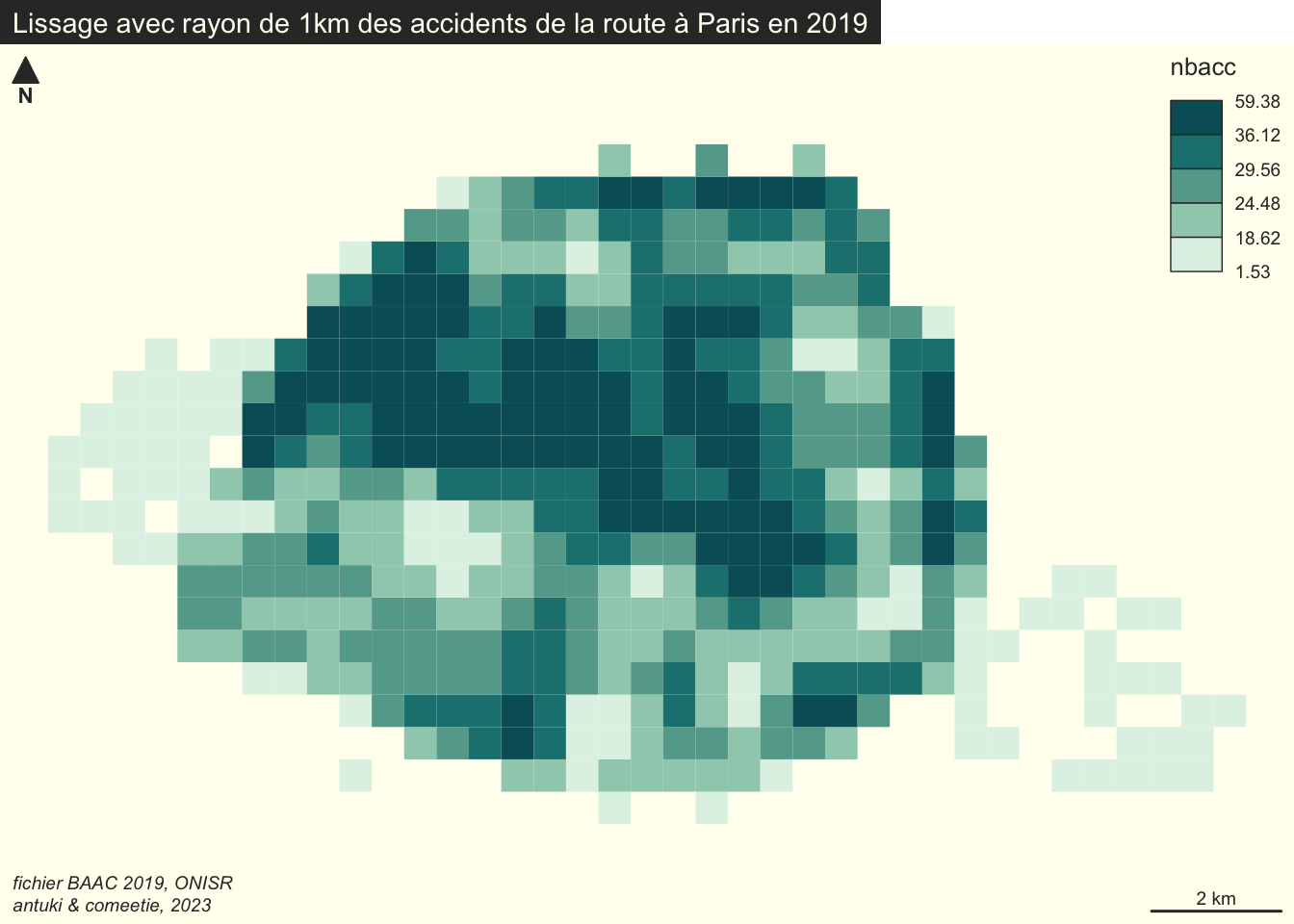
Exercice D : Grammaire des graphiques et ggplot2
Indice
Utilisez la fonction ggplot2::geom_barplot() pour faire un diagramme en barres. Et mettez en place la grammaire des graphiques dans ce cas précis.
- Ne garder que les véhicules
catvpour lesquels il y plus de 100 personnes accidentées ; - Créez une base de données avec une colonne
propqui correspond à la répartition en pourcentages de la gravitégravde l’accident (Tué, Blessé hospitalisé, Blessé léger et Indemne) pour chaque type de véhiculecatvimpliqué sélectionné dans le 1. - Veillez à transformer les deux variables en
factorpour bien les ordonner
gravdans l’ordre suivant :c("Tué", "Blessé hospitalisé","Blessé léger","Indemne")catvdans l’ordre du graphique qui correspond à l’ordre croissant de la part de personnes indemnes par catégorie de véhicule
- Réalisez le graphique (
geom_barplot,scale_fill_manual,theme_bw,geom_text,labs)
Solution
# 1. Ne garder que les véhicules +100 personnes accidentées
vehic_plus100_accidents <- accidents.2019.paris %>% st_drop_geometry %>%
count(catv) %>% filter(n>100) %>% pull(catv)
# 2. Créer bases de données avec pourcentages
gg <- accidents.2019.paris %>%
st_drop_geometry() %>%
filter(catv %in% vehic_plus100_accidents) %>%
mutate(catv_f = factor(catv)) %>%
mutate(grav_f = factor(grav, #3. facteur bien ordonné grav_f
levels = c(2,3,4,1),
labels = c("Tué", "Blessé hospitalisé",
"Blessé léger","Indemne")
)) %>%
count(catv_f,grav_f) %>%
group_by(catv_f) %>%
mutate(prop = 100*n/sum(n))
# facteur bien ordonné catv_f
ordre_catv_f <- gg %>%
filter(grav_f=="Indemne") %>%
arrange(prop) %>%
select(catv_f) %>%
pull()
# 4. Graphique
library(ggplot2)
graph <- ggplot(data = gg,aes(x = prop, y= factor(catv_f,levels=ordre_catv_f),fill = grav_f, group=grav_f))+
geom_bar(stat="identity") +
geom_text(aes(label = round(prop)),
position = position_stack(vjust = 0.5)) +
scale_fill_manual("Gravité (%)",
values = c("darkred","red","orange","darkgreen"))+
theme_bw()+
labs(title = "Répartition de la gravité des accidents par type de véhicule",
subtitle = "à Paris en 2019",
caption = "fichier BAAC 2019, ONISR\nantuki & comeetie, 2021",
x = "", y = "Type de véhicule")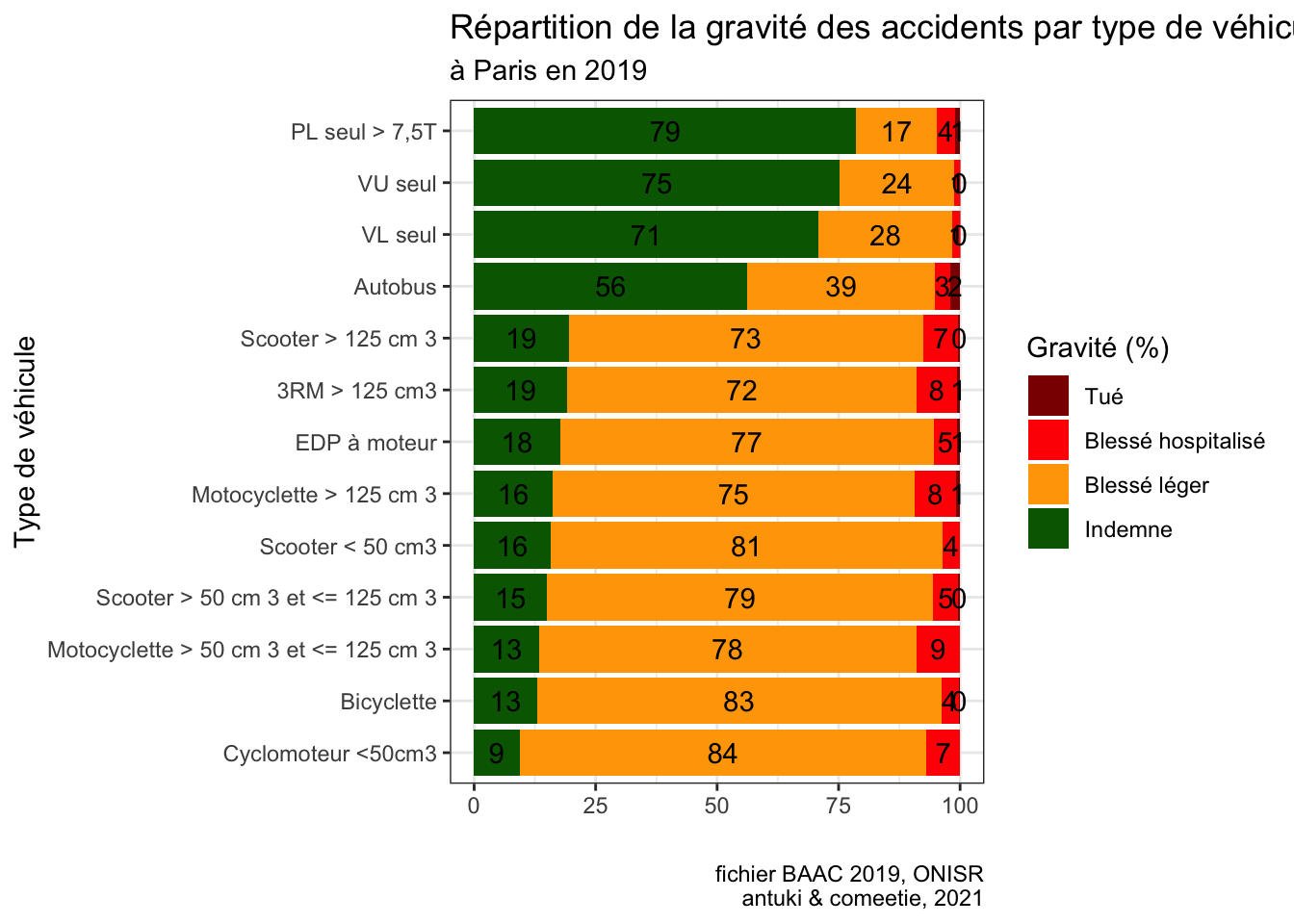
Notes de bas de page
Les iris sont un zonage statistique de l’Insee dont l’acronyme signifie « Ilots Regroupés pour l’Information Statistique ». Leur taille est de 2000 habitants par unité.↩︎